Kapitel 2
- Hvordan fungerer søgemaskiner?
- Hvad gennemsøger søgemaskiner?
- Hvad er et søgemaskineindeks?
- Søgemaskiner rangering
- Crawling: Kan søgemaskiner finde dine sider?
- Robots.txt
- Sådan behandler Googlebot robots.txt-filer
- Definition af URL parametre i GSC (Google Search Console)
- Kan crawlere finde alt dit vigtige indhold?
- Er dit indhold skjult bag login formularer?
- Stoler du på søgeformularer?
- Er tekst skjult i ikke-tekstindhold?
- Kan søgemaskiner følge din webstedsnavigation?
- Almindelige navigationsfejl, der kan forhindre crawlere i at se hele dit websted:
- Har du en klar informationsarkitektur?
- Bruger du sitemaps?
- Modtager crawler fejl, når de prøver at få adgang til dine URL’er?
- 4xx-koder: Når søgemaskine crawlere ikke har adgang til dit indhold på grund af en klientfejl
- 5xx-koder: Når søgemaskine crawlere ikke kan få adgang til dit indhold på grund af en serverfejl
- Pas på omdirigeringskæder!
- Indeksering: Hvordan fortolker og gemmer søgemaskiner dine sider?
- Kan jeg se, hvordan en Googlebot crawler ser mine sider?
- Fjernes sider nogensinde fra indekset?
- Fortæl søgemaskiner, hvordan dit websted skal indekseres
- Rangering: Hvordan rangerer søgemaskiner URL’er?
- Hvad ønsker søgemaskiner?
- Hvilken rolle spiller links i SEO?
- Rollens indhold har betydning i SEO
- Hvad er RankBrain?
- Hvad betyder dette for SEO’er?
- Engagementsdata: korrelation, årsagssammenhæng eller begge dele?
- Hvad Google har sagt
- Udviklingen af søgeresultater
- Lokaliseret søgning
Som jeg nævnte i kapitel 1, er søgemaskiner svarmaskiner. De eksisterer med det formål at finde, forstå og organisere internettets indhold, så de kan tilbyde de mest relevante resultater til de spørgsmål, som der bliver stillet via søgninger.
For at kunne vises i søgeresultater, skal dit indhold først være synligt for søgemaskiner. Det er uden tvivl den vigtigste brik i SEO puslespillet: Hvis dit websted ikke kan findes, er der ingen måde, du nogensinde vil dukke op på SERP’erne (siden med resultatsøgning fra søgemaskiner).
Hvordan fungerer søgemaskiner?
Søgemaskiner har tre primære funktioner:
- Crawl: Farte rundt på Internettet efter indhold, ser på koden/indholdet for hver URL, de finder.
- Indeks: Gemmer og organiser det indhold, der blev fundet under gennemsøgningsprocessen. Når en side først er i indekset, vises den som et resultat af relevante søgninger.
- Rangering: Angiver det indhold, der bedst svarer på en søgning, hvilket betyder, at resultaterne er sorteret efter de mest relevante og mindst relevante.
Hvad gennemsøger søgemaskiner?
Crawling er en opdagelsesprocessen, hvor søgemaskiner sender et team af robotter (kendt som crawlere eller edderkopper) ud for at finde nyt og opdateret indhold. Indhold kan variere – det kan være en webside, et billede, en video, en PDF fil osv. – men uanset formatet opdages indhold ved hjælp af links.
Googlebot starter med at hente et par websider og følger derefter linkene på disse websider for at finde nye URL’er. Ved at hoppe langs denne sti med links er crawleren i stand til at finde nyt indhold og føje det til deres indeks kaldet Caffeine – en stor database med fundne webadresser – der senere kan hentes, når en bruger søger information, hvor indholdet på den URL, har et godt match.
Hvad er et søgemaskineindeks?
Søgemaskiner behandler og gemmer information, de finder i et indeks, en enorm database med alt det indhold, de har opdaget og anser for at være godt nok til at vise for brugerne.
Søgemaskiner rangering
Når nogen udfører en søgning, søger søgemaskiner i indekset efter det meste relevante indhold og viser derefter dette indhold i håb om at det opfylder brugerens forespørgsel. Denne rækkefølge af søgeresultater efter relevans kaldes rangering. Generelt kan du antage, at jo højere et websted er rangeret, desto mere relevant mener søgemaskinen, at webstedet er i forespørgslen.
Det er muligt at blokere søgemaskine crawlere fra en del eller hele dit websted, eller instruere søgemaskiner i at undgå at gemme bestemte sider i deres indeks. Selvom der kan være grunde til at gøre dette, hvis du dog vil have dit indhold skal findes af søgemaskiner, skal du først sørge for, at det er tilgængeligt for crawlerne og kan indekseres. Ellers er det så godt som usynligt.
I slutningen af dette kapitel har du den kontekst, du har brug for, for at arbejde med søgemaskinen, snarere end imod den!
I SEO er ikke alle søgemaskiner ens
Mange begyndere spekulerer over den relative betydning af bestemte søgemaskiner. De fleste brugere ved, at Google har den største markedsandel, men hvor vigtigt er det at optimere for Bing, Yahoo og andre? Sandheden er, at trods eksistensen af mere end 30 store søgemaskiner, er SEO samfundet virkelig kun opmærksom på Google. Hvorfor? Det korte svar er, at Google er der, hvor langt de fleste brugere søger på nettet. Hvis vi inkluderer Google Billeder, Google Maps og YouTube (en del af Google), sker der mere end 90% af websøgninger på Google – det er næsten 20 gange så meget som Bing og Yahoo kombineret.
Crawling: Kan søgemaskiner finde dine sider?
Som du lige har lært, er det en forudsætning for at dukke op i SERP’erne at sikre, at dit websted bliver gennemgået og indekseret. Hvis du allerede har et websted, kan det være en god ide at starte med at se, hvor mange af dine sider der er i indekset. Dette giver en gode indsigt i, om Google gennemsøger og finder alle de sider, du vil have, og ingen af dem som ikke vil have.
En måde at kontrollere dine indekserede sider er “site: ditdomæne.dk”, en avanceret søgningsoperator. Start Google, og skriv “site: ditdomæne.dk” i søgefeltet. Dette viser resultater, som Google har i sit indeks for det angivne websted:
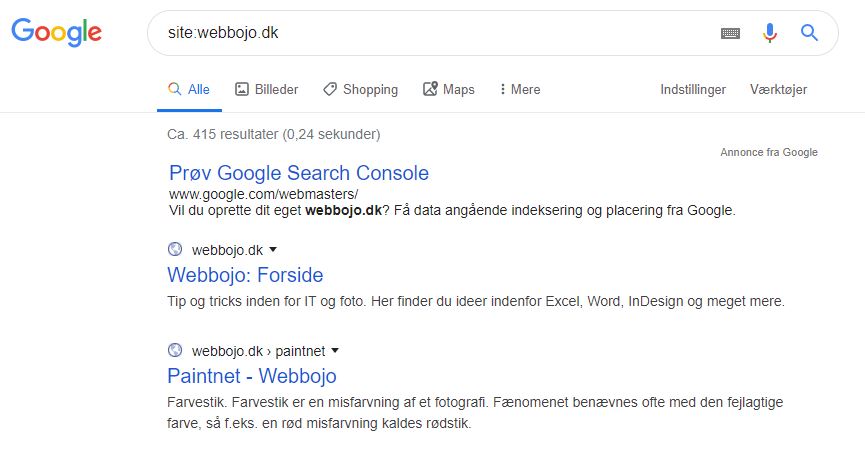
Antallet af resultater, som Google viser (se “Ca. XX resultater” ovenfor) er ikke nøjagtigt, men det giver dig en god idé om, hvilke sider der indekseres på dit websted, og hvordan de i øjeblikket vises i søgeresultater.
For mere nøjagtige resultater skal du overvåge og bruge indeksdækningsrapporten i Google Search Console. Du kan tilmelde dig en gratis Google Search Console-konto, hvis du ikke har en. Med dette værktøj kan du indsende sitemaps for dit websted og overvåge blandt andet, hvor mange indsendte sider, der faktisk er føjet til Googles indeks.
Hvis du ikke vises noget sted i søgeresultaterne, er der et par mulige grunde til:
- Dit websted er helt nyt og er ikke blevet gennemgået endnu.
- Der er ikke linket til dit websted fra eksterne websteder.
- Navnet på dit websted gør det svært for en robot at gennemgå det effektivt.
- Dit websted indeholder nogle grundlæggende kode kaldet crawler direktiver, som blokerer søgemaskiner.
- Dit websted er blevet straffet af Google for spam taktik.
Fortæl søgemaskiner, hvordan dit websted skal gennemses
Hvis du har brugt Google Search Console eller den avancerede søgningsoperatør “site: ditdomæne.dk” og opdager, at nogle af dine vigtige sider mangler i indekset, og/eller nogle af dine mindre vigtige sider er fejlagtigt indekseret, er der nogle optimeringer, du kan implementere for bedre at fortælle Googlebot, hvordan du vil have dit webindhold gennemgået. At fortælle søgemaskiner, hvordan du vil have gennemgået dit websted, kan give dig bedre kontrol over, hvad der ender i indekset.
De fleste mennesker er sikre på, at Google kan finde deres vigtige sider, men man glemme let, at der sandsynligvis er sider, som du ikke ønsker, at Googlebot skal finde. Disse kan omfatte ting som gamle URL adresser, der har et tyndt indhold, duplerede URL adresser (såsom sorterings- og filterparametre til e-handel), specielle promoverings kodesider, udkast- eller testsider osv.
Brug robots.txt til at dirigere Googlebot væk fra bestemte sider og sektioner på dit websted.
Robots.txt
Robots.txt-filer er placeret i rodmappe på dit websted (f.eks. ditdomæne.dk/robots.txt) og foreslår, hvilke dele af dit websteds søgemaskiner skal gennemgås, og hvilke der ikke bør gennemgå, samt den hastighed, hvorpå de gennemsøger dit websted, via specifikke robots.txt direktiver.
Sådan behandler Googlebot robots.txt-filer
- Hvis Googlebot ikke kan finde en robots.txt fil for et websted, fortsætter den med at gennemgå stedet.
- Hvis Googlebot finder en robots.txt-fil til et websted, følger den normalt forslagene og fortsætter med at gennemgå webstedet.
- Hvis Googlebot støder på en fejl under forsøg på at få adgang til et websteds robots.txt-fil og ikke kan afgøre, om en findes eller ej, vil den ikke gennemgå webstedet.
Optimer til crawlbudgettet!
Crawlbudgettet er det gennemsnitlige antal WRL’er, som Googlebot vil gennemgå på dit websted, før det forlades, så crawlbudgetoptimering sikrer, at Googlebot ikke spilder tid på at gennemgå gennem dine uvæsentlige sider med risiko for at ignorere dine vigtige sider. Crawlbudget er vigtigst på meget store websteder med titusinder af URL’er, men det er aldrig en dårlig ide at blokere crawlere fra at få adgang til det indhold, du bestemt ikke er interesseret i. Bare sørg for ikke at blokere en crawlers adgang til sider, som du har tilføjet andre direktiver, f.eks. kanoniske eller noindex tags. Hvis Googlebot er blokeret fra en side, kan den ikke se instruktionerne på denne side.
Ikke alle webrobotter følger robots.txt. Personer med dårlige intentioner (f.eks. indsamlere af e-mailadresser) laver bots, der ikke følger denne protokol. Faktisk bruger nogen robots.txt filer til at finde ud af, hvor du har placeret dit private indhold. Selvom det kan virke logisk at blokere crawler fra private sider, såsom login- og administrationssider, så de ikke vises i indekset, betyder placering af disse URL’er i en offentligt tilgængelig robots.txt-fil også, at folk med ondsindet hensigt lettere kan finde dem. Det er bedre at NoIndex disse sider og placere dem bag en login formular i stedet for at placere dem i din robots.txt-fil.
Definition af URL parametre i GSC (Google Search Console)
Nogle steder (mest almindeligt sider med e-handel) gør det samme indhold tilgængeligt på flere forskellige URL’er ved at tilføje visse parametre til webadresser. Hvis du nogensinde har handlet online, har du sandsynligvis indsnævret din søgning via filtre. For eksempel kan du søge efter “skjorte” på Amazon og derefter forfine din søgning efter størrelse, farve og stil. Hver gang du forfine, ændres webadressen let:
https://www.eksempel.dk/produkter/damer/kjoler/groen.htm
https://www. eksempel.dk/produkter/damer?kategori=kjoler&color=groen
https://www.eksempel.dk/butikindex.php?produkt_id=48&fremhaev=groen+kjole&kat_id =2&sessionid=123$affid = 43
Hvordan ved Google, hvilken version af URL adressen, der skal bruges til brugeren? Google gør et ret godt stykke arbejde med at finde ud af den repræsentative URL på egen hånd, men du kan bruge URL parameterfunktionen i Google Search Console til at fortælle Google nøjagtigt, hvordan du vil have dem til at behandle dine sider. Hvis du bruger denne funktion til at fortælle Googlebot “gennemsøge ingen webadresser med ____-parameter”, beder du i det væsentlige om at skjule dette indhold fra Googlebot, hvilket kan resultere i fjernelse af disse sider fra søgeresultater. Det er hvad du vil have, hvis disse parametre opretter dubletsider, men ikke ideelt, hvis du vil have disse sider indekseret.
Kan crawlere finde alt dit vigtige indhold?
Nu hvor du kender nogle taktikker til at sikre, at søgemaskine crawlere holder sig væk fra dit mindre vigtige indhold, så lad os se på de optimeringer, der kan hjælpe Googlebot med at finde dine vigtige sider.
Nogle gange vil en søgemaskine være i stand til at finde dele af dit websted ved at gennemgå det, mens andre sider eller dele muligvis er skjult af en eller anden årsag. Det er vigtigt at sikre, at søgemaskiner er i stand til at se alt det indhold, du vil have indekseret, og ikke kun din startside.
Stil dig selv dette spørgsmål: Kan en bot komme gennem dit websted og ikke kun til det?
Er dit indhold skjult bag login formularer?
Hvis du kræver, at brugere logger på, udfylder formularer eller besvarer undersøgelser, før de får adgang til bestemt indhold, kan søgemaskiner ikke se disse beskyttede sider. En crawler vil ikke kunne logge på.
Stoler du på søgeformularer?
Robotter kan ikke bruge søgefelter. Nogle personer tror, at hvis de placerer et søgefelt på deres websted, er søgemaskiner i stand til at finde alt, hvad deres besøgende søger efter.
Er tekst skjult i ikke-tekstindhold?
Ikketekst medieformer (billeder, video, GIF’er osv.) bør ikke bruges til at vise tekst, som du ønsker skal indekseres. Mens søgemaskiner bliver bedre til at genkende billeder, er der ingen garanti for, at de vil kunne læse og forstå det endnu. Det er altid bedst at tilføje tekst inden for <HTML> tags på din webside.
Kan søgemaskiner følge din webstedsnavigation?
Ligesom en crawler har brug for at finde dit websted via links fra andre sider, har den brug for en sti med links på dit eget sted for at kunne komme fra side til side. Hvis du har en side, du vil have søgemaskiner skal finde, men hvor den ikke er linket til fra andre sider, er den så god som usynlig. Mange websteder laver den kritiske fejl at strukturere deres navigation på måder, der er utilgængelige for søgemaskiner, hvilket hindrer at de blive fremhævet i søgeresultater.
Almindelige navigationsfejl, der kan forhindre crawlere i at se hele dit websted:
- Hvis du en mobil navigation, der viser andre resultater end din skærm navigation
- Enhver navigationsform, hvor menupunkterne ikke er i HTML, f.eks. JavaScript aktiverede navigationer. Google er blevet meget bedre til at gennemgå og forstå Javascript, men det er stadig ikke en perfekt metode. Den bedste måde at sikre, at bliver fundet, forstået og indekseret af Google, er ved at placere det i HTML.
- Tilpasning, eller visning af en unik navigation til en bestemt type besøgende i forhold til andre, kan søgemaskine crawler blive forvirret over.
- Glemmer at linke til en primær side på dit websted gennem din navigation – husk, links er de stier, som crawlere følger til nye sider!
Derfor er det vigtigt, at dit websted har en klar navigation og nyttige URL mappestrukturer.
Har du en klar informationsarkitektur?
Informationsarkitektur er den øvelse der omhandler organiseringen og mærkningen af indhold på et websted for at forbedre effektiviteten og muligheden for at det kan findes af brugerne. Den bedste informationsarkitektur er intuitiv, hvilket betyder, at brugere ikke behøver at tænke for meget over, hvordan man kommer gennem dit websted eller for at finde noget.
Bruger du sitemaps?
Et sitemap er bare, hvad det hedder: en liste over URL’er på dit websted, som crawlere kan bruge til at finde og indeksere dit indhold. En af de nemmeste måder at sikre Google finder dine sider med højeste prioritet er at oprette en fil, der opfylder Googles standarder og indsende den via Google Search Console. Selvom du sender et sitemap erstatter det ikke behovet for en god webstedsnavigation, men det kan bestemt hjælpe crawlere med at følge en sti til alle dine vigtige sider.
Sørg for, at du kun har inkluderet URL’er, du vil have indeksere af søgemaskiner, og sørg for at give crawlere konsistente instruktioner. Medtag f.eks. Ikke en URL i dit sitemap, hvis du har blokeret denne URL via robots.txt eller inkluder URL’er i dit sitemap, der er dubletter i stedet for den foretrukne, kanoniske version (jeg vil fortælle mere om kanonisering i kapitel 5).
Hvis dit websted ikke har andre sider, der linker til det, kan du muligvis stadig få det indekseret ved at indsende dit XML sitemap i Google Search Console. Der er ingen garanti for, at de inkluderer en indsendt URL i deres indeks, men det er værd at prøve!
Modtager crawler fejl, når de prøver at få adgang til dine URL’er?
I processen med at gennemgå URL’erne på dit websted kan en crawler støde på fejl. Du kan se Google Search Consoles rapporten “Crawl Errors” for at se URL’er, som dette muligvis sker for – denne rapport viser dig serverfejl og not found fejl. Serverlogfiler kan også vise dig dette såvel som en skattekiste af andre information, såsom gennemsøgningsfrekvens, men fordi adgang til og dissekering af serverlogfiler er en mere avanceret taktik, omtaler jeg dem ikke i denne Begyndervejledningen.
Før du kan gøre noget meningsfuldt med crawl fejlrapporten, er det vigtigt at forstå serverfejl og “not found” fejl.
4xx-koder: Når søgemaskine crawlere ikke har adgang til dit indhold på grund af en klientfejl
4xx-fejl er klientfejl, hvilket betyder, at den anmodede URL indeholder en dårlig syntaks eller ikke kan udføres. En af de mest almindelige 4xx-fejl er “404 – not found” fejlen. Disse kan forekomme på grund af en URL stavefejl, slettet side eller ødelagt omdirigering, bare for at nævne nogle eksempler. Når søgemaskiner rammer 404, har de ikke adgang til URL adressen. Når brugere rammer en 404, kan de blive frustrerede og forlade siden.
5xx-koder: Når søgemaskine crawlere ikke kan få adgang til dit indhold på grund af en serverfejl
5xx-fejl er serverfejl, hvilket betyder, at den server, websiden er placeret på, ikke opfyldte søgernes eller søgemaskinens anmodning om adgang til siden. I Google Search Consoles rapport “Crawl Error” er der en fane, der er dedikeret til disse fejl. Disse sker typisk, fordi anmodningen om URL’en udløb, så Googlebot opgav anmodningen. Se Googles dokumentation for at lære mere om at løse problemer med serverforbindelse.
Heldigvis er der en måde at fortælle både brugere og søgemaskiner, at din side er flyttet – 301 (permanent) omdirigeringen.
Lad os sige, at du flytter en side fra eksempel.dk/hunde/ til eksempel.dk/hvalpe/. Søgemaskiner og brugere har brug for en bro for at komme fra den gamle URL til den nye. Denne bro er en 301-omdirigering.
| Når du implementerer en 301: | Når du ikke implementerer en 301: | |
| Link værdien | Overførsler forbinder værdien fra sidens gamle placering til den nye URL. | Uden en 301 videregives værdien fra den forrige URL ikke til den nye version af URL’en. |
| Indeksering | Hjælper Google med at finde og indeksere den nye version af siden. | Tilstedeværelsen af 404 fejl på dit websted alene skader ikke søgningen i sig selv, men hvis du lader rangering/besøgte sider med 404 kan resultere i, at de falder ud af indekset, med placeringer og trafik lige så! |
| Brugeroplevelse | Gør det muligt for brugerne at finde den side, de leder efter. | At tillade dine besøgende at klikke på døde links fører dem til fejlsider i stedet for den tilsigtede side, hvilket kan være frustrerende. |
Selve 301-statuskoden betyder, at siden permanent er flyttet til en ny placering, så undgå at omdirigere webadresser til irrelevante sider – URL’er, hvor den gamle URL’s indhold faktisk ikke findes. Hvis en side vises i rangeringen efter en forespørgsel, og du benytter 301 på den til en URL med andet indhold, falder den muligvis i rangposition, fordi det indhold, der gjorde det relevant for den pågældende forespørgsel, ikke er der mere. 301’erne er magtfulde – flyt URL’er med omhu!
Du har også muligheden for at omdirigere en side til 302, men dette skal være forbeholdt midlertidige flytninger og i tilfælde, hvor overflytning af linkværdi ikke er så vigtig. 302’erne er ligesom en omvej. Du overflytter midlertidigt trafik gennem en bestemt rute, men det skal ikke være permanent.
Pas på omdirigeringskæder!
Det kan være vanskeligt for Googlebot at nå din side, hvis den skal gennem flere omdirigeringer. Google kalder disse “omdirigeringskæder”, og de anbefaler at begrænse dem så meget som muligt. Hvis du omdirigerer eksempel.dk/1 til eksempel.dk/2, og derefter senere beslutter at omdirigere det til eksempel.dk/3, er det bedst at eliminere mellemsiden og blot omdirigere eksempel.dk/1 til eksempel.dk/3.
Når du har sikret, at dit websted er optimeret til gennemsøgning, er det næste punkt at sikre, at det kan indekseres.
Indeksering: Hvordan fortolker og gemmer søgemaskiner dine sider?
Når du har sikret, at dit websted er gennemgået, er det næste punkt at sikre, at det kan indekseres. Det er rigtigt – bare fordi dit websted kan findes og gennemsøges af en søgemaskine, betyder det ikke nødvendigvis, at det gemmes i deres indeks. I det foregående afsnit om gennemsøgning drøftede vi, hvordan søgemaskiner opdager dine websider. Indekset er det sted, hvor dine fundne sider gemmes. Når en crawler har fundet en side, gengiver søgemaskinen den lige som en browser ville. I denne proces analyserer søgemaskinen sidens indhold. Alle disse oplysninger gemmes i dets indeks.
Læs videre for at lære om, hvordan indeksering fungerer, og hvordan du kan sikre dig, at dit websted finder vej til denne meget vigtige database.
Kan jeg se, hvordan en Googlebot crawler ser mine sider?
Ja, cache versionen af din side afspejler et øjebliksbillede af sidste gang Googlebot gennemsøgte den.
Google gennemsøger og cacher websider med forskellige frekvenser. Mere etablerede, velkendte websteder, der ofte lægger nyheder ud som https://www.bt.dk, vil blive gennemsøgt oftere end det meget mindre berømte websted for den lokale møntsamler klub, http://www.vielskergamlemønter.dk (hvis den så bare var ægte…)
Du kan se, hvordan din cache version af en side ser ud ved at klikke på rullemenuen ved siden af URL adressen i SERP og vælge “Cache”:

Du kan også se den tekst versionen af dit websted for at afgøre, om dit vigtige indhold gennemgås og cachelagres effektivt.
Fjernes sider nogensinde fra indekset?
Ja, sider kan fjernes fra indekset! Nogle af hovedårsagerne til, at en URL fjernes, inkluderer:
- URL’en returnerer en “ikke fundet” fejl (4XX) eller serverfejl (5XX) – Dette kan være utilsigtet (siden blev flyttet, og en 301 omdirigering ikke blev opsat) eller forsætlig (siden blev slettet og en 404 er tilføjet for at få den fjernet fra indekset)
- URL’en har fået tilføjet et noindex-metatag – Dette tag kan tilføjes af webstedsejere for at instruere søgemaskinen om at udelade siden fra dens indeks.
- URL’en er manuelt blevet straffet for overtrædelse af søgemaskinens retningslinjer for webmastere og blev som et resultat fjernet fra indekset.
- URL’en er blevet blokeret fra gennemsøgning med tilføjelse af et password, før besøgende kan få adgang til siden.
Hvis du mener, at en side på dit websted, der tidligere var i Googles indeks, ikke længere vises, kan du bruge URL inspektionsværktøjet til at se status for siden eller bruge Fetch as Google, der har en “Anmod om indeksering” funktion til indsendelse individuelle URL’er til indekset. (Bonus: GSCs “Fetch” værktøj har også en “render” indstilling, der giver dig mulighed for at se, om der er problemer med, hvordan Google fortolker din side).
Fortæl søgemaskiner, hvordan dit websted skal indekseres
Meta direktiver for robotter
Meta direktiver (eller “metatags”) er instruktioner, som du kan give søgemaskiner med hensyn til, hvordan du ønsker, at din webside skal behandles.
Du kan fortælle søgemaskine crawlere oplysninger som “ikke indeksere denne side i søgeresultater” eller “ikke overføre nogen link værdier til nogen links på siden”. Disse instruktioner udføres via Robots Metatags i <head> på dine HTML sider (mest almindeligt anvendte) eller via X-Robots-Tag i HTTP-overskriften.
Robots metatag
Robots metatag kan bruges inden for <head> i HTML’en på din webside. Det kan udelukke alle eller specifikke søgemaskiner. Følgende er de mest almindelige metadirektiver samt hvilke situationer du muligvis anvender dem i.
index/noindex fortæller søgemaskinerne, om siden skal gennemgås og opbevares i en søgemaskinens indeks så den kan vises. Hvis du vælger at bruge “noindex”, fortæller du crawlere, at du vil have siden ekskluderet fra søgeresultaterne. Som standard antager søgemaskiner, at de kan indeksere alle sider, så brug af “indeks” værdien er unødvendig.
- Hvornår du muligvis bruger: Du kan vælge at markere en side som “noindex”, hvis du prøver at trimme tynde sider fra Googles indeks på dit websted (f.eks.: brugergenererede profilsider), men du stadig ønsker at gøre dem tilgængelige for besøgende.
follow/nofollow fortæller søgemaskiner, om links på siden skal følges eller ikke følges. “Follow” resulterer i bots, følger linkene på din side og overfører linkets værdi til disse URL’er. Eller, hvis du vælger at bruge “nofollow”, vil søgemaskinerne ikke følge eller videregive nogen link værdi til linkene på siden. Som standard antages det, at alle sider har attributten “follow”.
- Hvornår du muligvis bruger: nofollow bruges ofte sammen med noindex, når du prøver at forhindre, at en side indekseres, såvel som at forhindre, at webcrawleren følger links på siden.
noarchive bruges til at begrænse søgemaskiner i at gemme en cache kopi af siden. Som standard opbevarer søgemaskiner synlige kopier af alle sider, de har indekseret, tilgængelige for brugere via cache linket i søgeresultaterne.
- Hvornår du muligvis bruger: Hvis du har et websted med e-handel, og dine priser ændres regelmæssigt, kan du overveje noarchive tagget for at forhindre, at brugeren kan se forældede priser.
Her er et eksempel på meta robots noindex, nofollow-tag:
<! DOCTYPE html>
<html>
<head> <meta name = "robots" content = "noindex, nofollow" />
</head>
<body> ... </body>
</html>
Dette eksempel udelukker alle søgemaskiner fra at indeksere siden og fra at følge eventuelle links på siden. Hvis du vil ekskludere flere crawler, som f.eks. Googlebot og bing, er det okay at bruge flere robot ekskluderings tags.
X-Robots-Tag
X-robot tagget bruges i http hovedet i din URL, hvilket giver mere fleksibilitet og funktionalitet end metakoder, hvis du vil skalere blokeringen af søgemaskiner, fordi du kan bruge almindelig udtryk, blokere ikke HTML filer og anvende sitewide noindex tags.
For eksempel kan du nemt ekskludere hele mapper eller filtyper (som webbojo.dk/excel/gamle-eksempler-til noindex):
<Files ~ “\ /? No \ -excel\ /.*”> Header set X-Robots-tag “noindex, nofollow” </Files>
Eller specifikke filtyper (som PDF-filer):
<Files ~ “\ .pdf $”> Header set X-Robots-tag “noindex, nofollow” </Files>
Flere oplysninger om Meta Robot tags kan du finde hos Googles Robots Meta Tag-specifikationer.
WordPress tip:
I Kontrolpanel > Indstillinger > Læsning, skal du sørge for, at feltet “Søgemaskine synlighed” ikke er markeret. Dette forhindrer søgemaskiner i at besøge dit websted via din robots.txt fil!
At forstå de forskellige måder, du kan påvirke gennemsøgning og indeksering, hjælper dig med at undgå de almindelige faldgruber, der kan forhindre, at dine vigtige sider bliver fundet.
Rangering: Hvordan rangerer søgemaskiner URL’er?
Hvordan sikrer søgemaskiner, at når nogen indtaster en forespørgsel i søgefeltet, at de til gengæld får relevante resultater? Denne proces kaldes rangering eller rækkefølgen af søgeresultater fra de mest relevante til de mindst relevante for en bestemt forespørgsel.
For at bestemme relevansen bruger søgemaskiner algoritmer, en proces eller formel, hvormed lagret information hentes og ordnes på en meningsfuld måde. Disse algoritmer har gennemgået mange ændringer gennem årene for at forbedre kvaliteten af søgeresultaterne. Google foretager for eksempel algoritmejusteringer hver dag – nogle af disse opdateringer er mindre kvalitets justeringer, mens andre er kerne/større algoritmeopdateringer, der er implementeret for at tackle et specifikt problem, som Penguin der tackler link spam.
Hvorfor ændres algoritmen så ofte? Forsøger Google bare at holde os vågne? Selvom Google ikke altid afslører detaljer om, hvorfor de gør, som de gør, ved vi, at Googles mål når de foretager algoritmejusteringer, er at forbedre den samlede søgekvalitet. Derfor svarer Google på spørgsmål til algoritmeopdatering med noget i retning af: “Vi laver kvalitetsopdateringer hele tiden.” Dette indikerer, at hvis dit websted skuffer efter en algoritmejustering, kan de sammenligne det med Google’s Quality Guidelines eller Search Quality Rater Guidelines, begge er meget informative med hensyn til, hvad søgemaskinerne ønsker.
Hvad ønsker søgemaskiner?
Søgemaskiner har altid ønsket den samme ting: At give nyttige svar på brugerens spørgsmål i det mest nyttige format. Hvis det er sandt, hvorfor ser det så ud til, at SEO er anderledes nu end i de foregående år?
Tænk over det i form af, at nogen lærer et nyt sprog.
Til at begynde med er deres forståelse af sproget meget rudimentær – “Se Peter Løbe.” Over tid begynder deres forståelse at blive dybere, og de lærer semantik – betydningen bag sproget og forholdet mellem ord og sætninger. Til sidst, med nok øvelse, kender den studerende sproget godt nok til endda at forstå nuancer og er i stand til at give svar på selv vage eller ufuldstændige spørgsmål.
Da søgemaskiner lige var begyndt at lære vores sprog, var det meget lettere at snyde systemet ved at bruge tricks og taktikker, der faktisk strider mod kvalitetsretningslinjer. Tag for eksempel brugen af søgeord. Hvis du ville rangeres efter et bestemt søgeord som “sjove vittigheder”, kan du muligvis tilføje ordene “sjove vittigheder” en masse gange på din side og gøre det i håb om at øge din placering med dette udtryk:
Velkommen til sjove vittigheder! Vi fortæller de sjoveste vittigheder i hele verden. Sjove vittigheder er sjove og vanvittige. Din sjove vittighed venter. Læn dig tilbage og læs sjove vittigheder, fordi sjove vittigheder kan gøre dig glad og sjovere. Nogle sjove foretrukne sjove vittigheder.
Denne taktik var en forfærdelig brugeroplevelser, og i stedet for at grine af sjove vittigheder, blev folk bombarderet af irriterende, svært læsbar tekst. Det har måske fungeret i fortiden, men det var aldrig det, søgemaskinerne ønskede.
Hvilken rolle spiller links i SEO?
Når vi taler om links, kunne det strengt taget betyde to ting. Backlinks eller “indgående links” er links fra andre websteder, der peger på dit websted, mens interne links er links på dit eget websted, der peger på dine andre sider (på det samme sted).
Links har historisk set spillet en stor rolle i SEO. Meget tidligt havde søgemaskinerne brug for hjælp til at finde ud af, hvilke webadresser der var mere pålidelige end andre for at hjælpe dem med at bestemme, hvordan de skulle rangere søgeresultater. Beregning af antallet af links, der peger på et givet sted, hjalp dem med at gøre dette.
Backlinks fungerer meget på samme måde som i det virkelige liv mundtlige henvisninger. Lad os tage en hypotetisk butik, Karls isenkræmmer, som et eksempel:
- Henvisninger
fra andre = godt tegn på autoritet
- Eksempel: Mange forskellige mennesker har alle fortalt dig, at Karls isenkræmmer er den bedste i byen.
- Henvisninger
fra dig selv = ensidigt, ikke et godt tegn på autoritet
- Eksempel: Karl hævder, at Karls isenkræmmer er den bedste i byen.
- Henvisninger
fra irrelevante kilder eller lav kvalitetskilder = ikke et godt tegn på
autoritet og kan endda få dig markeret som spam
- Eksempel: Karl betalte for at folk, der aldrig har besøgt hans isenkræmmer butik, fortæller andre, hvor god den er.
- Ingen
henvisninger = uklar autoritet
- Eksempel: Karls isenkræmmer er muligvis god, men du har ikke været i stand til at finde nogen, der har en mening, så du kan ikke være sikker.
Dette er grunden til, at PageRank blev oprettet. PageRank (del af Googles kernealgoritme) er en linkanalysealgoritme opkaldt efter en af Googles grundlæggere, Larry Page. PageRank estimerer vigtigheden af en webside ved at måle kvaliteten og mængden af links, der peger på den. Antagelsen er, at jo mere relevant, vigtig og troværdig en webside er, jo flere links har den opnået.
Jo mere naturlige backlinks du har fra websteder med høj autoritet (betroede), jo bedre er dine odds for at rangere højere inden for søgeresultaterne.
Rollens indhold har betydning i SEO
Der ville ikke være noget ide i links, hvis de ikke dirigerede brugeren hen til noget. Dette noget er indhold! Indhold er mere end bare ord; det er noget, der skal bruges af brugeren – der er videoindhold, billedindhold og selvfølgelig tekst. Hvis søgemaskiner er svarmaskiner, er indhold det middel, hvormed søgemaskinerne leverer disse svar.
Hver gang nogen udfører en søgning, er der tusindvis af mulige resultater, så hvordan beslutter søgemaskinerne sig for, hvilke sider brugeren vil finde værdifulde? En stor del af afgørelsen af, hvor din side skal rangeres for en given forespørgsel, er hvor godt indholdet på din side svarer til forespørgslens intention. Med andre ord, stemmer denne side overens med de ord, der blev søgt, og hjælper den med at udføre den opgave, som brugerne forsøgte at udføre?
På grund af dette fokus på brugertilfredshed og opgaveydelse, er der ingen direkte benchmarks for, hvor langt dit indhold skal være, hvor mange gange det skal indeholde et nøgleord, eller hvad du lægger i dine header tags. Alt sammen kan spille en rolle i hvor godt en side fungerer i søgningen, men fokusset skal være på de brugere, der læser indholdet.
I dag, med hundreder eller endda tusindvis af rangerings signaler, har de tre bedste været ret konsistente: links til dit websted (som fungerer som et tredjeparts troværdighedssignaler), indhold på siden (kvalitetsindhold, der opfylder en brugers intention) og RankBrain.
Hvad er RankBrain?
RankBrain er maskinlæringskomponenten i Googles kernealgoritme. Maskinindlæring er et computerprogram, der fortsætter med at forbedre sine forudsigelser over tid gennem nye observationer og træningsdata. Med andre ord, det lærer altid, og fordi det altid lærer, skal søgeresultaterne konstant forbedres.
Hvis RankBrain f.eks. lægger mærke til en URL med lavere placering, der giver et bedre resultat til brugerne end URL’erne med den højere placering, kan du være sikker på, at RankBrain vil justere disse resultater, flytte det mere relevante resultat højere op og nedgradere de mindre relevante sider som et sideprodukt.
Som de fleste ting med søgemaskinen, ved vi ikke nøjagtigt, hvad RankBrain består af, men tilsyneladende gør folkene hos Google det heller ikke.
Hvad betyder dette for SEO’er?
Da Google fortsætter med at udnytte RankBrain til at fremme det mest relevante, nyttige indhold, er vi nødt til at fokusere på at opfylde brugerens intention mere end nogensinde før. Tilbyd den bedst mulige information og oplevelse til brugeren, der måske havner på din side, og du har taget det første store skridt i retningen af at klare dig godt i en RankBrain verden.
Engagementsdata: korrelation, årsagssammenhæng eller begge dele?
Med Google placeringer er engagementsdata sandsynligvis delkorrelation og delårsagssammenhæng.
Når vi siger engagementsmålinger, mener vi data, der repræsenterer, hvordan brugere interagerer med dit websted ud fra søgeresultater. Dette inkluderer ting som:
- Klik (besøg fra søgning)
- Tid på side (tiden, som besøgende har brugt på en side, før den forlades)
- Bounce rate (procentdelen af alle websteds sessioner, hvor brugere kun har set en side)
- Pogo-sticking (klik på et organisk resultat og derefter hurtigt tilbage til SERP for at vælge et andet resultat)
Mange tests har indikeret, at engagementsmålinger harmonerer med højere placering, men årsagssammenhæng er blevet drøftet varmt. Er målinger for godt engagement bare vejledende for højt rangerede websteder? Eller rangeres websteder højt, fordi de har gode engagementsmåls data?
Hvad Google har sagt
Da de aldrig har brugt udtrykket “direkte rangeringssignal”, har Google været klar over, at de bestemt bruger klik data til at ændre SERP for bestemte forespørgsler.
Ifølge Googles tidligere chef for Search Quality, Udi Manber:
”Selve rangeringen påvirkes af klikdataene. Hvis vi opdager, at 80% af brugerne for en bestemt forespørgsel klikker på nr. 2 og kun 10% klikker på nr. 1, vil vi efter et stykke tid regner ud at # 2 sandsynligvis er den, brugerne ønsker, og så vi skifter det.”
En anden kommentar fra den tidligere Google ingeniør Edmond Lau bekræfter dette:
”Det er temmelig tydeligt, at enhver rimelig søgemaskine ville bruge klikdata i deres egne resultater for at fodre rangerginen for at forbedre kvaliteten af søgeresultaterne. Den faktiske mekanik for, hvordan klikdata bruges, er ofte hemmelige, men Google gør det indlysende, at der bruges klikdata med deres patenterede systemer som rangjusterede indholds emner.”
Fordi Google har brug for at bevare og forbedre søgekvaliteten, ser det uundgåeligt ud til, at engagements data er mere end korrelation, men det ser ud til, at Google ikke vil til at kalde engagementsdata for “rangeringssignal”, fordi disse data bruges til at forbedre søgekvaliteten, og rangering af individuelle URL’er kun et biprodukt af dette.
Udviklingen af søgeresultater
Tilbage, da søgemaskinerne var knap så sofistikeret, so de er i dag, blev udtrykket “10 blå links” møntet på beskrivelsen af SERP’s flade struktur. Hver gang en søgning blev udført, ville Google returnere en side med 10 organiske resultater, hver i samme format.
I dette søgelandskab var SEO’s hellige gral at holde fast i placeringen som nr. 1. Men så skete der noget. Google begyndte at tilføje resultater i nye formater på deres søgeresultatsider, kaldet SERP funktioner. Nogle af disse SERP-funktioner inkluderer:
- Betalte annoncer
- Udvalgte uddrag
- Folk spørger også bokse
- Kort
- Videns panel
- Websitelinks
Og Google tilføjer nye hele tiden. De eksperimenterede endda med “zero-result SERPs”, et fænomen, hvor kun et resultat fra Knowledge Graph blev vist på SERP uden resultater under det bortset fra en mulighed for at “se flere resultater.”
Tilføjelsen af disse funktioner forårsagede en vis panik af to hovedårsager. For det første har mange af disse funktioner fået organiske resultater til at blive skubbet yderligere ned på SERP. Et andet biprodukt er, at færre brugere klikker på de organiske resultater, da flere forespørgsler besvares på selve SERP.
Så hvorfor skulle Google gøre dette? Det hele går tilbage til søgeoplevelsen. Brugeradfærd angiver, at nogle forespørgsler er bedre løst med forskellige indholdsformater. Bemærk, hvordan de forskellige typer SERP-funktioner matcher de forskellige typer forespørgselsformål.
| Forespørgsel hensigt | Mulig SERP-funktion udløst |
| Informativt | Udvalgt uddrag |
| Informativt med et svar | Viden graf/øjeblikkeligt svar |
| Lokal | Kortpakke |
| Transaktion | Shopping |
Vi vil tale mere om hensigt i kapitel 3, men indtil videre er det vigtigt at vide, at svar kan leveres til brugere i en lang række formater, og hvordan du strukturerer dit indhold kan påvirke det format, det vises i søgningen.
Lokaliseret søgning
En søgemaskine som Google har sit eget proprietære indeks over lokale virksomhedsfortegnelser, hvorfra den opretter lokale søgeresultater.
Hvis du udfører lokalt SEO arbejde for en virksomhed, der har en fysisk placering, som kunder kan besøge (f.eks.: tandlæge) eller for en virksomhed, der benytter transport for at besøge deres kunder (eks: blikkenslager), skal du sørge for, at du gør krav, verificerer og optimerer en gratis Google My Business Listing.
Når det kommer til lokaliserede søgeresultater, bruger Google tre hovedfaktorer til at bestemme rangeringen:
- Relevans
- Afstand
- Fremhævelse
Relevans
Relevans er, hvor godt en lokal virksomhed matcher, hvad søgeren leder efter. For at sikre, at virksomheden gør alt, hvad der kan for at være relevant for søgere, skal du sørge for, at virksomhedsoplysningerne udfyldes grundigt og nøjagtigt.
Afstand
Google bruger din geo-placering til bedre at opfylde dine lokale resultater. Lokale søgeresultater er ekstremt følsomme over for nærheden, hvilket henviser til placeringen af søgeren og/eller den placering, der er angivet i forespørgslen (hvis søgeren inkluderede en).
Organiske søgeresultater er følsomme over for en søgers placering, dog sjældent så udtalt som i lokale pakkeresultater.
Fremhævelse
Med fremhævelse som en faktor prøver Google at belønne virksomheder, der er velkendte i den virkelige verden. Ud over en virksomheds offline fremhævelse ser Google også på nogle online faktorer for at bestemme lokal rangering, såsom:
Anmeldelser
Antallet af Google-anmeldelser, som en lokal virksomhed modtager, og fornemmelsen af disse anmeldelser har en markant indflydelse på deres evne til at rangere i lokale resultater.
Citater
En “virksomhedscitation” eller “virksomhedsfortegnelse” er en webbaser.
Lokale placeringer er påvirket af antallet og konsistensen af lokale forretningscitationer. Google henter data fra en lang række kilder ved kontinuerligt at udarbejde sit lokale forretningsindeks. Når Google finder flere ensartede referencer til en virksomheds navn, placering og telefonnummer, styrker det Googles “tillid” til gyldigheden af disse data. Dette fører derefter til, at Google kan vise virksomheden med en højere grad af tillid. Google bruger også oplysninger fra andre kilder på nettet, såsom links og artikler.
Organisk placering
SEO’s bedste praksis gælder også for lokal SEO, da Google også overvejer et websteds placering i organiske søgeresultater, når de bestemmer lokal placering.
I det næste kapitel lærer du bedste fremgangsmåder på din websiden, til at hjælpe Google og brugere med at forstå dit indhold bedre.